Our Products
Our Products
Our Products
The Executive Guide to Retrieval Augmented Generation (RAG)
An executive overview of Retrieval Augmented Generation (RAG) and how it enables more accurate, reliable, and production-ready AI systems.

Modern AI systems entered the enterprise with enormous promise, and immediate friction. While their ability to generate fluent, confident responses is undeniable, their behavior often proves incompatible with enterprise reality. When outputs are produced without access to internal knowledge, or based on outdated data, it does more than disrupt operations; it erodes trust with customers, regulators, investors, and the teams tasked with acting on those insights.
In high-stakes environments, this lack of grounding is not a minor deployment detail, it is a fundamental business constraint. Retrieval Augmented Generation (RAG) emerged not as a leap in model intelligence, but as a practical architectural bridge across this gap.
By tethering a large language model (LLM) to an organization’s approved, proprietary knowledge sources, RAG injects authoritative data directly into the model’s reasoning process at the moment of query. This allows organizations to leverage AI systems without the prohibitive cost of retraining models or the risk of losing control over data privacy. The result is not necessarily smarter systems, but safer, more predictable, and more governable ones.
This guide is written for leaders who recognize the potential of AI but require clarity on where RAG fits, where it excels, and where its limitations begin. It treats RAG not as a silver bullet, but as a foundational design pattern, one that enables rapid adoption while establishing clear guardrails around what AI can and cannot be trusted to do.
What Is RAG: A System Design Pattern for the Enterprise
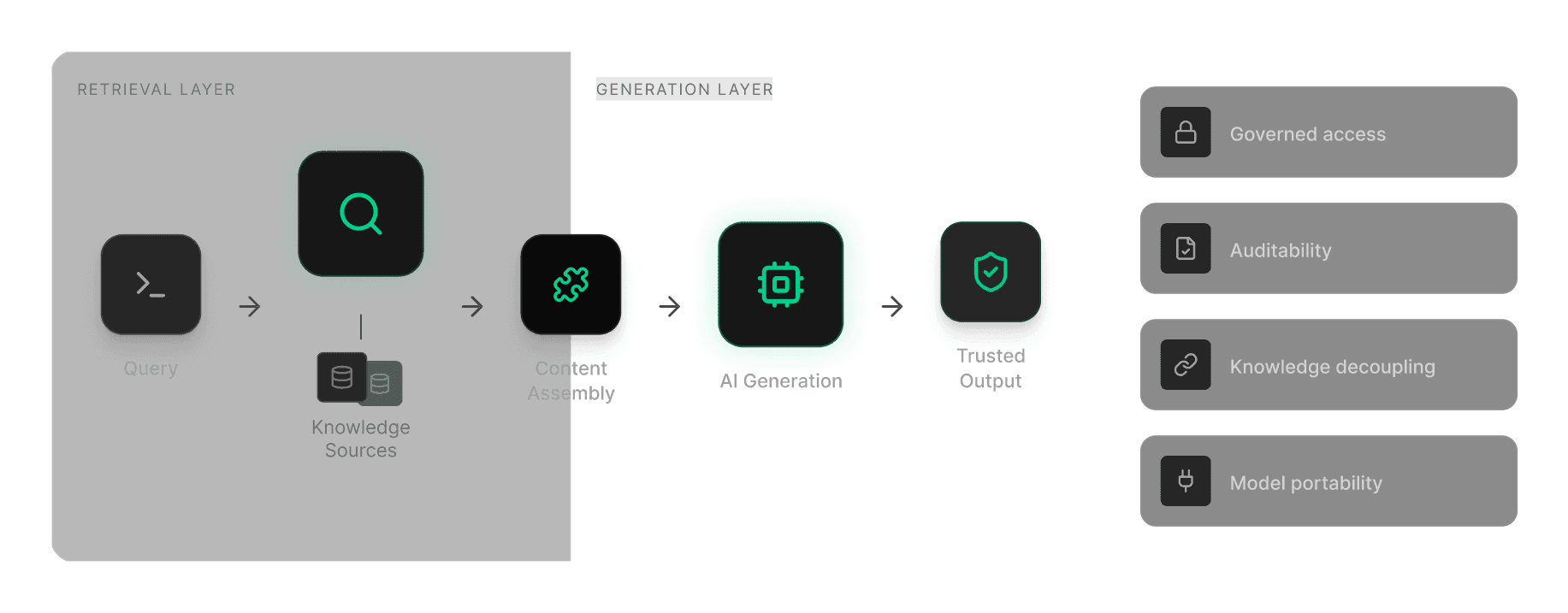
At its core, a RAG system dynamically retrieves relevant knowledge at the time of a query and injects that information into the model’s context. Instead of relying on the model’s frozen training knowledge, the system guides the model using up-to-date, approved sources selected at runtime.
What distinguishes enterprise-grade RAG is the shift from raw capability to rigorous control. This architecture provides four strategic advantages:
Governed Retrieval: Information is sourced only from approved internal or licensed repositories.
Observability: The process is auditable, enabling teams to trace which source materials influenced a given output.
Knowledge Decoupling: Knowledge storage is separated from language generation, allowing organizations to update information continuously without retraining models.
Model Portability: Because knowledge lives outside the model, enterprises can change or upgrade underlying models, without re-architecting their data pipelines.
The Problems RAG Solves
RAG addresses the most common failure mode in enterprise AI: The Knowledge Gap. LLMs are frozen the moment their training ends. They do not know your current financial targets, updated policies or customer-specific agreements. When forced to bridge these gaps from memory, models hallucinate, producing fluent, confident, but fabricated answers that are nearly impossible to audit and risky to act upon.
By retrieving source material at query time, RAG transforms the model from a creative generator into a subject matter expert with an open textbook. This enables traceability, improves reliability, and reduces regulatory exposure.
How RAG Works: A System-Level View
At a high level, RAG inserts a retrieval layer between a user query and model generation. The objective is not to change how the model speaks, but to control what information it is allowed to reference.
A production-grade RAG flow typically unfolds in five stages:
Query Transformation: The system captures the user intent and prepares the query for search, often expanding or refining it beyond original phrasing.
Retrieval: The query is matched against an indexed knowledge base. It often uses a mix of semantic and keyword search.
Re-Ranking: Initial retrieval may surface dozens of candidates. A secondary scoring step priorities the most relevant passages, reducing noise before generation.
Context Assembly: These high-signal snippets are bundled with the original query into a structured context package.
Grounded Generation: The LLM generates a response using the retrieved context as its primary source of information.
The strategic shift is from recall to synthesis. Knowledge lives outside the model in a managed runtime, allowing updates in hours rather than months and enabling inspection, citation, and review. RAG reduces hallucinations, but does not eliminate them, hence governance and monitoring remain essential.
RAG as a Shared Infrastructure
In a mature AI stack, RAG sits between data infrastructure and application logic. Many early pilots stall when RAG is treated as a localized feature embedded in a single chatbot or application. This creates predictable failure modes: redundant costs, governance gaps, and knowledge silos.
Organizations seeing durable results treat RAG as a shared infrastructure. By centralizing retrieval logic and permissions, they create a common grounding layer that multiple applications can rely on. In practice, this enables the same governed RAG capability to support research, operations, compliance, and strategy, ensuring consistent, trusted context across the enterprise.
RAG vs Adjacent Approaches
RAG is often confused with neighbouring techniques, but the distinctions matter:
RAG vs Prompt Engineering: Prompts influence how a model responds while RAG governs what information it can use.
RAG vs Fine-Tuning: Fine-tuning embeds knowledge into the model, which is slow, costly, and hard to update. RAG keeps knowledge external, making it better suited for volatile information.
RAG vs Traditional Search: Search retrieves documents, while RAG synthesizes across them.
RAG vs Agentic Systems: RAG is a grounding pattern that answers “What is true?” Agentic systems focus on execution, determining what should happen next.
Prompts shape responses, search retrieves documents, fine-tuning enforces behavior, RAG grounds facts, and agents move work forward.
Why Enterprises Are Adopting RAG
Enterprise adoption of RAG is driven less by ambition and more by necessity. Organizations are prioritizing AI systems they can deploy safely, explain clearly, and operate at scale.
Primary Drivers: Trust and Control
Accuracy and Hallucination Control: Grounding responses in approved evidence reduces unsupported outputs and enables use in regulated or customer-facing roles.
Data Control: Sensitive internal data remains within governed infrastructure rather than embedded into model weights.
Knowledge Velocity: Updating indexed content is faster and cheaper than retraining models.
Secondary Drivers: Agility and Risk
Model Portability: Externalised knowledge allows organisations to change models to optimize for cost or performance, without re-architecting systems, reducing vendor lock-in.
Incremental Rollout: Enterprises can start with one domain and scale using a consistent pattern.
The Leadership Reality Check: RAG does not make AI systems more intelligent; it makes them more disciplined. It improves how reliably existing reasoning is applied to the right facts. This distinction is often what allows initiatives to move from pilots to production.
Enterprise RAG Use Cases
Use Case | Business Problem | How RAG Is Used | Why RAG (vs Alternatives) | Enterprise Value |
|---|---|---|---|---|
Investment & Market Research | Fragmented filings, transcripts, and internal research scattered across systems | Retrieves multi-source research at query time to synthesise insights | Market data changes too frequently for fine-tuning. RAG supports freshness | Faster research cycles, consistent narratives, improved analyst leverage |
Regulatory & Compliance | Guidance is ambiguous, frequently updated | Grounds responses in current policies and interpretations | Audibility is mandatory, RAG allows easy source traceability | Reduced compliance risk, defensible AI outputs |
Operational Intelligence | Tribal knowledge is scattered across tickets and run books | Retrieves relevant procedures and prior incident histories for issue resolution | Operational knowledge is too distributed and dynamic to embed in a model | Faster resolution, fewer escalations |
Legal & Contract Analysis | High-volume review requires precision and historical precedent | Retrieves clauses and precedent for analysis | Hallucinations carry material risk, RAG enables citation-driven workflows | Accelerated review cycles, audit-grade traceability |
Executive Briefing | Leaders need rapid synthesis across internal and external signals | Assembles reports and strategy context for briefings | Executives require explainability and source confidence to trust recommendations | Faster preparation, improved alignment, higher confidence |
Across these patterns, RAG succeeds when the objective is grounded synthesis, not autonomous execution.
Limitations, Risks, and the Functional Ceilings
RAG is not a set-and-forget solution. Nor is it a cure for a broken data strategy. Most failures stem from weaknesses in the knowledge supply chain; how information is sourced, indexed, refreshed, and governed.
Critical Failure Points
Data Quality Bottleneck: If irrelevant or incomplete evidence is surfaced, the model will confidently synthesise incorrect conclusions. This “Garbage In, Garbage Out” dynamic is amplified by messy data or poorly tuned indexes.
Freshness Lag: When source documents are updated, but retrieval indexes are not refreshed, systems may continue to surface obsolete guidance.
Permission Leakage: Without strict Role-Based Access Control (RBAC) in the retrieval layer, sensitive content can be inadvertently exposed to unauthorized users, creating security and compliance risk.
Scalability & Latency: As knowledge bases scale, retrieval costs and response times can rise quickly. Without optimisation, performance becomes unpredictable and expensive.
RAG fails silently. Unlike a system outage that triggers an alert, a RAG system will continue to produce fluent, credible-looking outputs even when retrieval quality degrades. Sustaining accuracy requires continuous evaluation and disciplined data management, treating enterprise data as a living asset, not a static library.
Functional Ceilings
RAG is a grounding tool, not an autonomous agent. It has distinct reasoning boundaries:
The Execution Gap: Standard RAG is one-shot. It summarises found facts but cannot perform multi-step reasoning, coordinate actions across systems, or provide continuous monitoring
Static Nature: RAG is a reactive retrieval design. It does not learn proprietary information over time or improve its own intelligence without human intervention.
Executive Takeaway: If the question is “What facts should the model know?”, RAG is the right tool. If the question becomes “What should happen next?”, RAG alone has reached its ceiling.
What This Means for Enterprise Leaders
RAG is neither optional nor sufficient. It is a necessary control layer that makes enterprise AI governable, auditable, and operationally usable.
Guiding Principles
Treat RAG as infrastructure, not a feature: Fragmented pilots create technical debt, inconsistent controls, and duplicated efforts.
Prioritise retrieval quality over model choice: Sustainable advantage comes from quality, structure, and governance of enterprise knowledge rather than marginal differences in model capability.
Design for evolution beyond RAG: High-quality grounding creates the preconditions for advanced systems that support increasingly complex decision workflows.
The path forward requires clear-eyed optimism. Sustainable advantage will come from disciplined execution rather than generative novelty. It will come from grounded intelligence that can ultimately support intelligent action, not just fluent output.